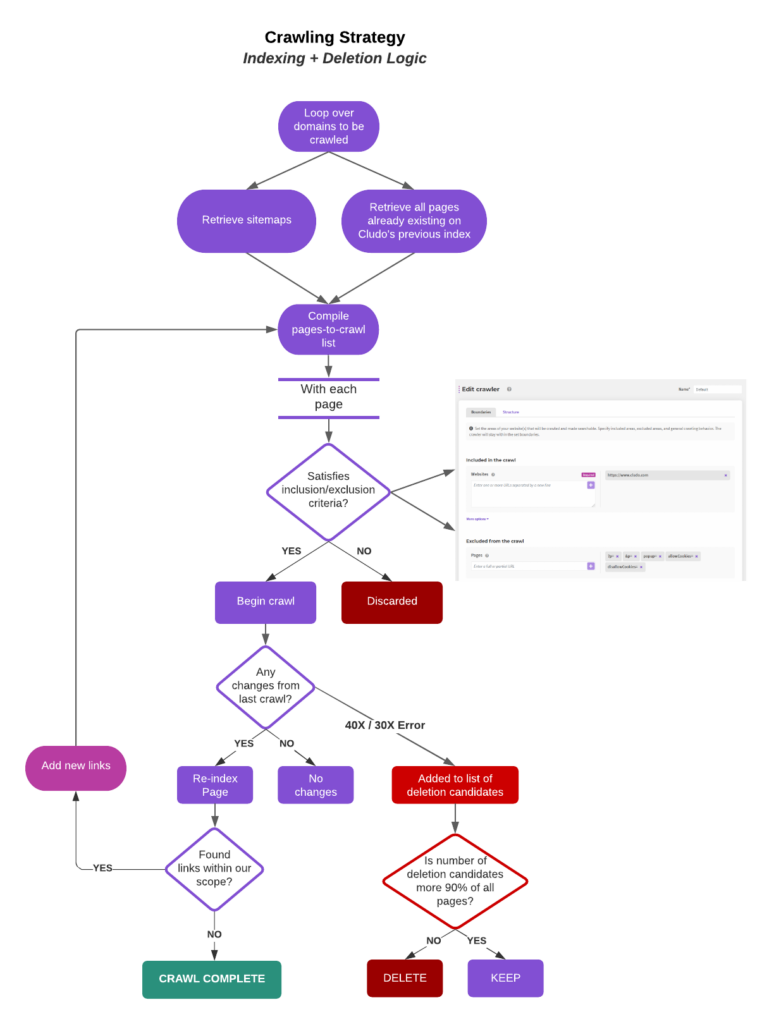
How does the crawler index and delete pages?
Cludo’s strategy for crawling sites is based on finding as many pages as possible within the user-defined domains, indexing, and storing their content.
Cludo’s crawlers run every 24 hours, plus the time it takes to complete the most recent crawl.
The step-by-step process can be seen in detail in the diagram at the end of the article and will be explained further below:
Crawling: Step-by-step process
1: Sites to be crawled
The crawling algorithm will loop over all domains to be crawled and retrieve their sitemaps (if they exist). If a previous crawl is stored, all pages that are already indexed will be added, ultimately forming a list of sites to be crawled.
2: Crawl start
The crawl begins, extracting all the content available from each page in the list. Cludo’s crawler will first check if an older version of a page already exists in the index. If that is the case, the crawler will compare the two versions, and if they are different, the page will be re-indexed. Otherwise, the page will remain in the index database without changes.
3: Organic crawl
Every time a link is found on the content that satisfies the inclusion/exclusion criteria defined in the crawler settings of the MyCludo platform, it will automatically be added to the list to be crawled.
4: Errors and deletion
Whenever the crawler encounters an HTTP response status code equal to 30X or 40X, the page will be added to a list of deletions candidates. When the crawl finishes, if the number of deletions candidates does not exceed 90% of the whole index, they will be removed. You can find an overview of the deletion logic below.
| Response | Action |
|---|---|
| 20X | Keep |
| 30X | Drop |
| 4XX | Drop |
| 50X | Keep |
| Missing required field | Keep |
Note: Our crawlers will automatically drop any page that returns a 4XX error code, except for 429 (Too Many Requests). Pages with a 429 response will be re-crawled later.
Files are only crawled every 25 days. This means that deleted files can persist in the index for up to 25 days before getting dropped from the index. If you ever in the need to have files deleted manually, you can contact support.
5: Crawl finish
Once every page of the list has been dealt with and the potential deletions are processed, the crawl will be considered as finished, and search results will be updated.