How does Cludo index files?
As long as a file is machine-readable (not an image), Cludo is able to crawl its content along with the information sent with the HTTP headers.
How to enable or disable file indexing
By default, the crawler is configured to index files for the specified domain. You can enable or disable this setting in the crawler settings by following these steps:
- In the navigation menu, go to Configuration › Crawlers.
- Stay on the Boundaries tab and scroll down to the bottom of the crawler settings.
- Locate the Crawl files toggle and switch it on or off as needed.
This allows you to control whether the crawler indexes files for your domain.
File titles
It is possible to select how the file title should be extracted by selecting one of the following:
- HTTP header
- Automatic
- File element
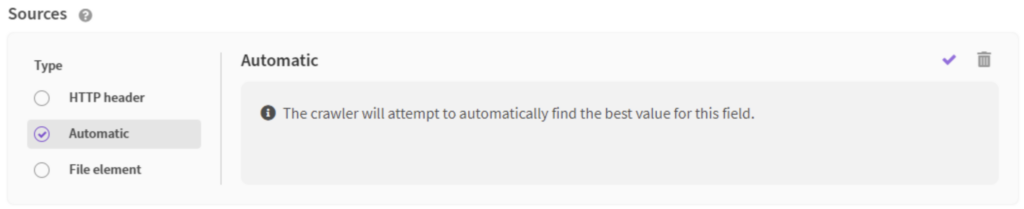
Automatic
The default option is Automatic, where the crawler will automatically look for a meta title and resort to the file name if none is found. You can view the meta title of a file by opening its properties. The field “Title” reflects the meta title:
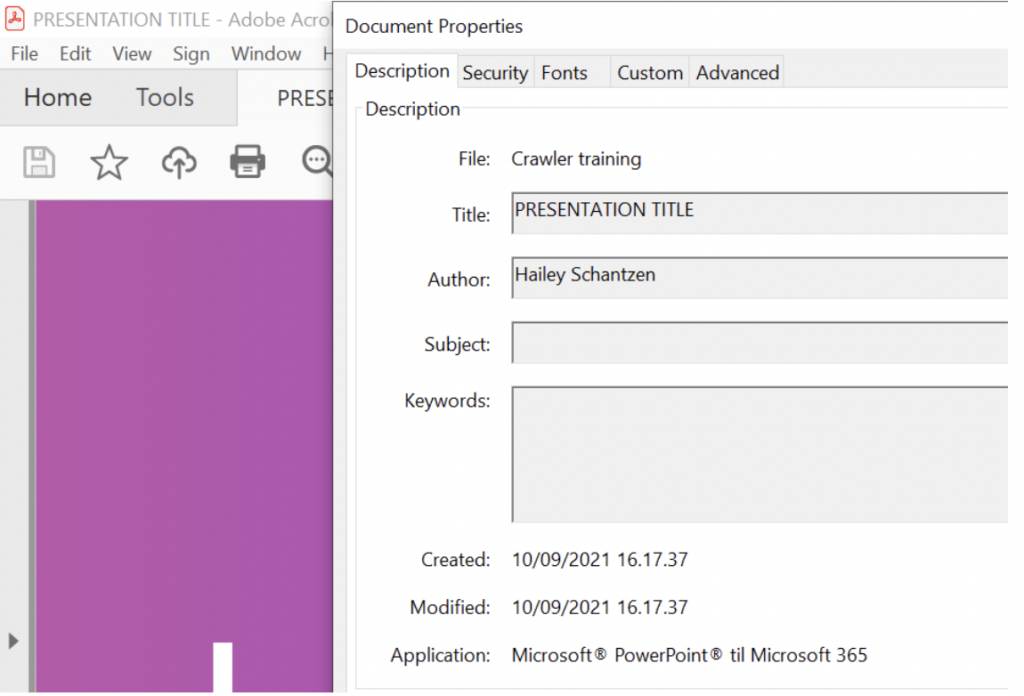
If a meta title doesn’t exist, we will extract the file name (URL) instead and use that as the search result title.
File element
Can be set to Content Disposition File name or Response File Name.
HTTP header
Choose a specific HTTP header the title should be extracted from.
File descriptions
For the file description, you can choose between HTTP header or Automatic. When using Automatic (recommended), the description in the search result will be based on the entire text content of the file, which the crawler is able to extract as long as the content is not an image. This makes it possible for the file to appear as a result for any search term that exists within its text content.
Displaying custom fields for documents
It is possible to set up custom fields for files to either make them searchable or to display that information in the results (only applicable to custom SERPs or API solutions). To do so, click Add custom field and configure as needed.
Need help configuring file crawling? Don’t hesitate to contact support.