Crawlers
What is a crawler?
A crawler is usually the first step to creating a functional site search. The crawler is in charge of checking all available pages on the given domain(s) and indexing any pages and files according to the configuration. Once indexed, the pages and files can be searched for by leveraging an engine.
When indexing pages, the crawler will always account for unique pages, so the same URL will never be indexed twice by the same crawler.
How does a Crawler find pages and files?
XML sitemaps
Sitemaps are structured files, usually auto-generated, that provide a list of all the pages on a site. A sitemap file will typically contain the URL of each page along with its last modified time.
When the crawler locates a sitemap, it will look through all the URLs and attempt to index all pages and files that match the crawler settings.
Note: The crawler will automatically look for a sitemap in the root of included websites (i.e. yourwebsite.com/sitemap.xml).
Following links on the site
In addition to the sitemap, the crawler will always detect available links on the pages it comes across, follow, and index those pages that match the crawler settings.
The crawler will only ever crawl and index URLs that match the domain(s) added in its settings.
How to set up a crawler
A crawler searches a URL for pages and adds them to a search index to be used by an engine.
Boundaries
- In the navigation, select Configuration › Crawlers.
- Click the New button at the top of the table.
- Give the crawler a name in the Name field.
- Insert a URL in the Websites field.
- Click the + Icon to add the URL.
- Optional: Open More options to insert a URL in the Page Exceptions field that the crawler is allowed to index even if it doesn’t match the domain entered. Click the + Icon to add the URL.
- Optional: Open More options to insert a URL to a sitemap in the Sitemaps field. Click the + Icon to add the URL. Note that the crawler will automatically detect any sitemaps declared in the robots.txt file or located as /sitemap.xml under the root of the domain.
- Optional: Under Excluded from the crawl
- Insert part of a URL or a URL parameter in the Pages field. Click the + Icon to add the URL.
- Open More options to insert a regular expression in the URL regex field. Click the + Icon to add the URL.
- Click Next: Structure to the bottom right (only displayed if it’s a new crawler), or click the Structure tab at the top.
Structure
- Set the Language to the language of the website.
- Optional: Open More options to change the Content type. The default is Web pages – only if the crawler is strictly set up to index people profiles, it should be set to People directory.
- Update the default fields as needed to control exactly what content is picked up for each of those.
- Under Page Fields and File fields, click on Add custom field + to add additional fields for the crawler to pick up.
- Type the name of the field in the Field name field.
- Optional: Enable the Field required toggle to only index pages that contain this field. If the crawler does not find any value for a required field, the page will not be added to the index.
- Click on Add source +.
- Select the type of source under Type.
- Fill out the Value field and any other required field for the field type.
- Optional: Select the correct data type in the Data type drop down.
- Optional: Write a default value in the Default value field. If the crawler doesn’t find any value for the field, the page will instead be assigned this value. This is especially useful when the field is set to be required to ensure all pages will still be indexed.
- Optional: Click Add source + again to add a fallback source for finding the field value in different ways.
- Click Apply.
- Click Save Crawler.
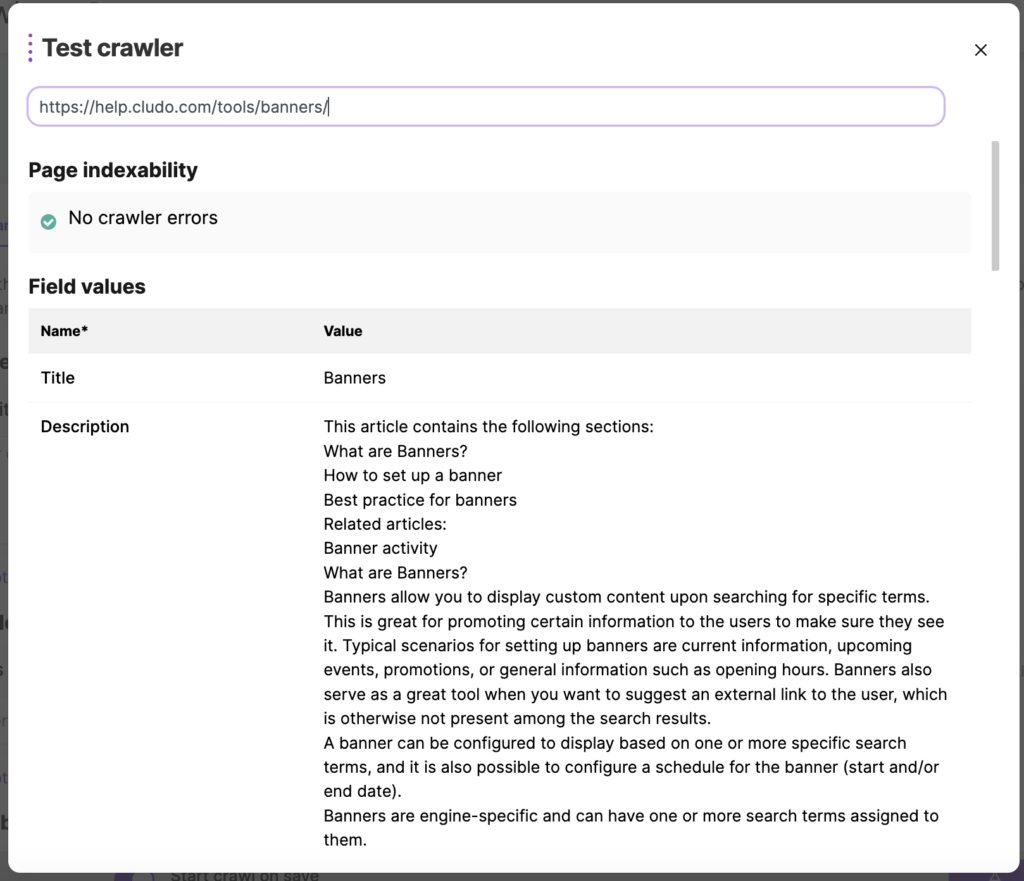
How to test a crawler
In order to test the crawler configuration, it is possible to make crawl against a specific URL to see which data will be indexed for the page.
Are you missing any content on your page or are you wondering why a specific page isn’t occurring in the index? Use the Test crawler feature to identify if a page hasn’t been indexed due to an error or a specific crawler setting.
If a page shows no crawler errors when being tested but doesn’t appear in the Page Inventory, it’s probably because it hasn’t been properly naturally linked to, which makes the crawler unable to navigate to it and crawl it. You can read about exploring your page inventory in this article.
- In the navigation, select Configuration › Crawlers
- Select the crawler you wish to test
- Click the flask icon next to the Save crawler button
- In the test crawler modal, insert the URL of a page to crawl in the Insert test URL field
- Hit Enter
- Verify the Field values table has the expected value for each field
Best practices for crawlers
Setting up a crawler is a required step in configuring a functional search engine. You should consider both the configuration of the crawler as well as how many crawlers you should create.
Starting a crawler
You can always start a crawler by pressing Save Crawler if Start crawl on save is toggled on.
Language
Crawlers are language-specific, so sites with support for multiple languages should configure one crawler per language. Remember to set the correct language in the crawler settings, since this determines in which language the pages should be analyzed (read more about language support).
Fields
Title and Description
Title and Description are both default and required fields. These are also the most important fields when it comes to good relevance in search.
Title
For Title, choose the source that best applies to the page structure on your site. In most cases, all pages have an H1, so you could use the First H1 option to have this as the search result title. You could also leverage the <title> tag or metadata such as the og:title.
Description
For Description, one thing that is very important to keep in mind is that the fields configured in the crawler determine what is searchable. Make sure that what you configure for this field is a reflection of the content on the page.
It would not be a good idea to set the description to just fetch your meta description, since in that case, the actual page content would not be searchable. If you would like to display the meta description in the results, you could of course set the Description field to fetch the meta description, but then you’d want to add a custom field that grabs the entire page content to make sure this is searchable.
You will also want to make sure that the description doesn’t go too broad – e.g. grabbing navigation or footer elements that are present on all pages (for example by just fetching the entire <body> element). If that was the case, all of your pages would appear as results if the visitor searched for something that’s present in the navigation or footer, ultimately decreasing relevance.
Custom fields
When setting up a crawler, you will want to consider not only what fields should be displayed, but also which fields should be searchable.
For example, you may not want to display your meta keywords in the result itself, but it would still be a good idea to set this up as a crawled field to make sure they’re searchable.
On top of the above, the fields you define in the crawler can also be used for boosting, so taking the example above, you could have a field for your meta keywords that you could later apply boosting to, ensuring that results that have the search term in their meta keywords are ranked higher.
Using fallbacks
Most sites have a number of different page types that do not always follow the same structure. To accommodate for this, it is a good idea to use fallbacks. For example, when defining your Title field, you could have the primary source be First H1, but have a fallback to Page title (the <title> field).
Meta tags vs. XPath
When configuring a crawler, at some point configuration must be done to clarify where in the HTML specific data can be found.
For a lot of fields the data is either found in the Meta tags in the header of the HTML or in the body. If the data is in the body of the HTML it can be found using XPath. However, since XPath is a series of instructions to the HTML structure, it means any change to the HTML structure can cause the XPath to be invalid.
To avoid this risk, it is generally recommended to configure crawler fields based on metadata. An exception to this would of course be the Description, where it is encouraged to write an XPath that grabs the page content.
Multiple sites
When there is a need for a global search across different sites that have a different structure, it is recommended to configure multiple crawlers in order to account for these differing structure, since you’ll want to configure the page fields differently. All of the crawlers can later be added to the same engine.
If all of the sites have the same structure, it can be beneficial to keep them in one crawler for maximum efficiency.
Avoiding duplicate results
If you’re dealing with duplicate results in your search, there’s probably an explanation for it. Visit this page to learn more!
Need help? Don’t hesitate to contact support!